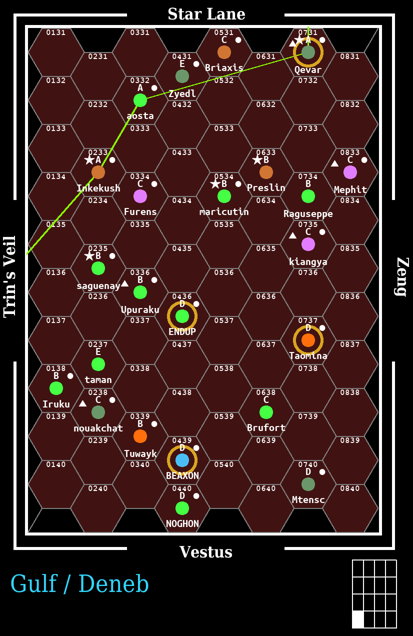
Gulf (De M) Subsector
For the Gulf Subsector in the Reaver's Deep Sector see here
| Gulf Subsector | |
|---|---|
 | |
| Sector | Deneb |
| Capital | None |
| Number of Systems | 23 |
| Stellar and Economic data | data page |
| Majority Control | Third Imperium - 100% |
| Map Key | Map Key |
{kind=link}
Gulf (De M) Subsector was originally designated District 221 and was the last subsector in Deneb to be admitted into the Imperium, in 550.
Description[edit]
Gulf, subsector M of Deneb, has 23 worlds, of which 19 have native gas giants. There are no Asteroid (As) belts, three Desert (De) worlds, no Garden (Ga) worlds, no Ice-capped (Ic) worlds, eight Poor (Po) worlds, no Vacuum (Va) worlds, and one Water (Wa) or Ocean (Oc) world.
Native Sophonts[edit]
There are no sophont races native to the Gulf Subsector.
Physical Astrography[edit]
Mains and Branches[edit]
Traces and Clusters[edit]
- Lintl Cluster: A single system
- Tuwayk Cluster
Rifts, Voids, and Jump Bridges[edit]
Other Astrographic Features[edit]
History & Background[edit]
Gulf is the home of the 193rd Fleet, with its headquarters at Qevar (Deneb 0731). The 193rd achieved fame in the Fifth Frontier War by its stubborn defense of the Regina Subsector. The only ground it gave in the entire war was Louzy (Spinward Marches 1604), although it left formidable system defense forces in the system which dogged Zhodani supply lines and ultimately doomed the Zhodani's Siege of Efate. The 193rd moved trailing during the fleet realignment that took place shortly after the conclusion of the war. [1]
Historical Eras[edit]
Major Historical Events Timeline[edit]
There is no Duke in Gulf. The Duchies of Vincennes, Zeng and Trin’s Veil together manage Gulf Subsector’s various affairs. The only glimmer of strength in Gulf is in Tuwayk (Deneb 0339) near the Rimward border, which has enough power to resist the exploitation and privateering that is endemic to the subsector.
The Baraccai Technum operates its merchant freighters here.
Politics and Diplomacy : Milieu 1116[edit]
Gulf, subsector M of Deneb has 23 worlds, of which 19 have native gas giants. The estimated population for the subsector is 96 billion sophonts (not necessarily humans). There are three High population (Hi) worlds, one Moderate population (Ph) world, 13 Non-industrial (Ni) worlds, six Low population (Lo) worlds, and no Barren (Ba) worlds. There is one Agricultural (Ag) world versus no Pre-Agricultural (Pa) worlds, and three Non-Agricultural (Na) worlds. There is one Rich (Ri) world versus two Industrial (In) worlds. There are no Asteroid (As) belts, three Desert (De) worlds, no Garden (Ga) worlds, no Ice-capped (Ic) worlds, eight Poor (Po) worlds, no Vacuum (Va) worlds, and one Water (Wa) or Ocean (Oc) world. There are five Naval bases in the subsector, four Scout bases, and one Way station. The Imperial nobility includes 23 Knights, one Baronet, two Barons, one Marquis, one Viscount, three Counts, and no Dukes. The highest population world is Beaxon (Deneb 0439). The highest tech level is E at Saguenay (Deneb 0235) and Qevar (Deneb 0731). The average technology level is 9 (with most between 6 and 11).
Polity Listing[edit]
The Third Imperium, Domain of Deneb in Gulf has jurisdiction over all of the worlds.
- Third Imperium (Imperial powers)
- Duchy of Trin’s Veil
- Duchy of Vincennes
- Duchy of Zeng
- Various member systems and worlds.
Demographics[edit]
Significant populations of the following races (sophont species) reside within this subsector:
World Listing[edit]
Territorial Overview[edit]
The Gulf (De M) Subsector is defended by 193rd Fleet.
Politics and Diplomacy : New Era[edit]
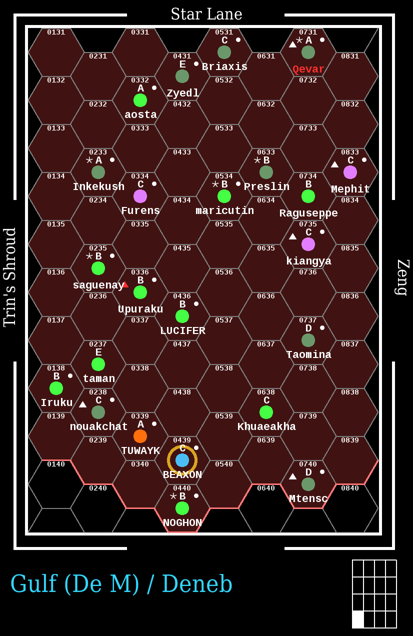
| Gulf Subsector | |
|---|---|
 | |
| Sector | Deneb |
| Capital | Qevar (Deneb 0731) |
| Number of Systems | 23 |
| Stellar and Economic data | data page |
| Majority Control | Regency of Deneb - 100% |
| Map Key | Map Key |
Gulf, subsector M of Deneb has 23 worlds, of which 19 have native gas giants. The estimated population for the subsector is 22 billion sophonts (not necessarily humans). There are four High population (Hi) worlds, no Moderate population (Ph) worlds, 13 Non-industrial (Ni) worlds, six Low population (Lo) worlds, and no Barren (Ba) worlds. There is one Agricultural (Ag) world versus no Pre-Agricultural (Pa) worlds, and three Non-Agricultural (Na) worlds. There are two Rich (Ri) worlds versus three Industrial (In) worlds. There are no Asteroid (As) belts, three Desert (De) worlds, no Garden (Ga) worlds, no Ice-capped (Ic) worlds, eight Poor (Po) worlds, no Vacuum (Va) worlds, and one Water (Wa) or Ocean (Oc) world. There are six Naval bases in the subsector, five Scout bases, and one Way station. The highest population world is Beaxon (Deneb 0439). The highest tech level is F at Inkekush (Deneb 0233), Saguenay (Deneb 0235), Aosta (Deneb 0332), and Qevar (Deneb 0731). The average technology level is 11 (with most between 8 and 13).
Polity Listing[edit]
The Regency of Deneb in Gulf has jurisdiction over all of the worlds. The subsector capital is Qevar (Deneb 0731).
Demographics[edit]
Significant populations of the following races (sophont species) reside within this subsector:
- Non-Human Races
- None
World Listing[edit]
Territorial Overview[edit]
No information available.
References & Contributors (Sources)[edit]
- Gary L. Thomas, Joe Fugate. "Data/Library: Deneb." The Travellers' Digest 19 (1990): 24-30.
- Rob Caswell. "Domain of Deneb: Sector Data." MegaTraveller Journal 3 (1992): 47-58.
- Dave Nilsen. The Regency Sourcebook (Game Designers Workshop, 1995), 64.
- Mongoose Traveller: Deneb Sector (UWP only)
- EXTERNAL LINK: Sunbane Data
- ↑ Dave Nilsen. The Regency Sourcebook (Game Designers Workshop, 1995), 64.